Data Science : 5 Visual Programming using Orange Tool
Here in this blog we will discuss about more features of Orange Tool. To learn basic of Orange Tool then see my previous blog named Data Science: Orange Tool Basic Overview . In this blog I will show how to Split our data in training data and testing data in Orange , how to use cross validation in Orange.
Visual Programming
Interactive data exploration for rapid qualitative analysis with clean visualizations. Graphic user interface allows you to focus on exploratory data analysis instead of coding, while clever defaults make fast prototyping of a data analysis workflow extremely easy. Place widgets on the canvas, connect them, load your datasets and harvest the insight.
Creating the workflow
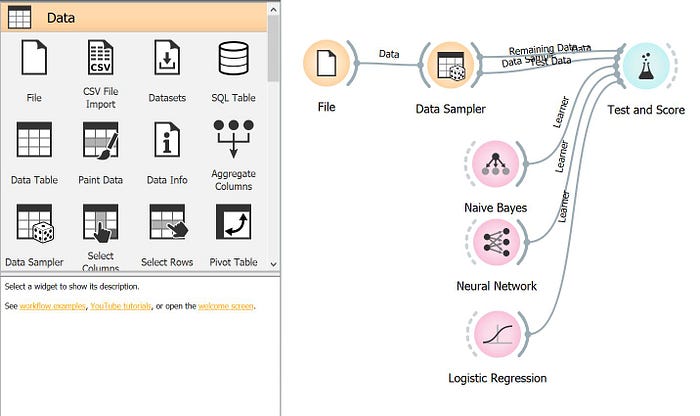
First we use File widget in the canvas and load the inbuilt Heart Disease dataset in the workflow.

Next send the input data to widget Data Sampler. Data Sampler selects a subset of data instances from an input data set. It outputs a sampled and a complementary data set (with instances from the input set that are not included in the sampled data set). The output is processed after the input data set is provided and Sample Data is pressed. Here I sampled the data 70% output sampled data and 30% will be complementary data set.

Now send the sample data from Data Sampler to Test and Score widget. The widget tests learning algorithms. Different sampling schemes are available, including using separate test data. The widget does two things. First, it shows a table with different classifier performance measures, such as classification accuracy and area under the curve. Second, it outputs evaluation results, which can be used by other widgets for analyzing the performance of classifiers, such as ROC Analysis or Confusion Matrix.
The sample data from Test and Score is send to three different learning algorithms namely Neural Network, Naive Bayes and Logistic Regression.

Sampling of data using Cross Validation in Orange
Cross-validation splits the data into a given number of folds (usually 5 or 10). Cross-validation is primarily used in applied machine learning to estimate the skill of a machine learning model on unseen data. That is, to use a limited sample in order to estimate how the model is expected to perform in general when used to make predictions on data not used during the training of the model.

Splitting of data in training data and than testing data in Orange
To split the data into train and test dataset, we will send the 70% of the sampled data from Data Sampler as the train data and remaining 30% data as the test data by clicking on the link between Data Sampler and Test and Score. In there set the link from Data Sample box to Data box and Remaining Data box to Test Data as shown in below figure.
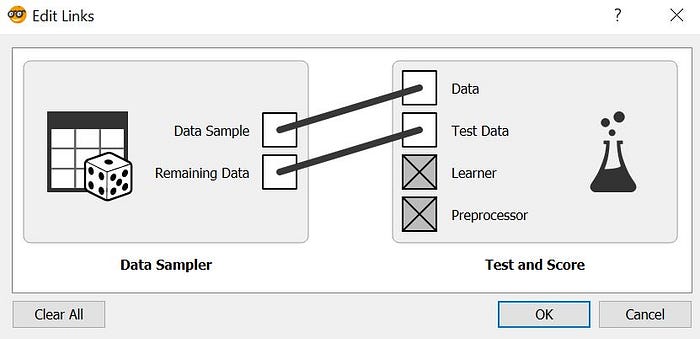
Now, there will be two flows setup from Data Sampler to Test and Score widget: one flow which sends the 70% Data Sample i.e Train data to Test and Score and second flow which sends the 30% Remaining Data i.e Test Data to Test and Score widget.
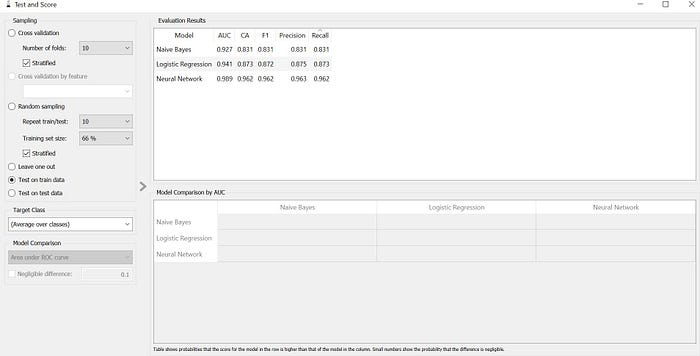
Now get the comparison scores of the three diferent algorithms by testing on the train data. To do so double click on the Test and Score widget and choose the option of Test on train data there and get the scores for all the three algorithm.
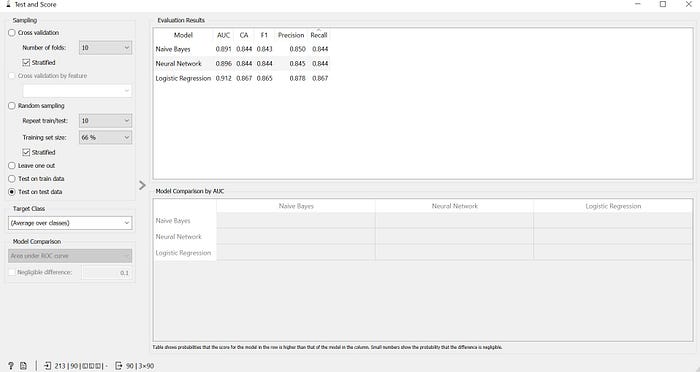
To test the learning algorithms on the basis of the test data choose the option of Test on test data in the Test and Score widget.
Conclusion:
Here I have explore on how we can sample our data and compare different learning algorithms to find out which is the best algorithm for our data set using the Orange tool.
